AI search indexing is how large language models and AI search engines ingest, structure, and interpret your business data so they can answer questions about you in natural language.
Summary
Unlike classic SEO indexing, which matches keywords to pages, AI engines reconstruct your brand as an entity graph: who you are, what you offer, where you operate, and how people talk about you across the web. For multi-location brands, this means AI must be able to parse your corporate‑to‑location hierarchy, services, reputation, and external citations as one coherent system.
Birdeye helps multi-location brands operationalize this AI indexing work at scale. By combining centralized data governance with real-time AI visibility, Birdeye ensures your business is accurately represented and consistently cited across AI surfaces.
This article explores how AI systems actually understand your business and what it takes to build an AI-ready data architecture that earns visibility, accuracy, and trust.
Table of contents
- The AI crawling reality: How AI systems “see” your business differently
- The AI indexing stack: The layers AI systems rely on
- Schema Markup 2.0: Moving from SEO checkbox to AI communication protocol
- The schema priority matrix: What matters most for AI understanding
- The multi-location data challenge: Building hierarchical entity architecture
- Beyond Schema: The complete data layer for AI indexing
- The citation network: Building external data consistency
- Practical implementation: The technical roadmap
- Birdeye Search AI: Built to make AI search indexing real for multi-location brands
- FAQs on AI search indexing
The AI crawling reality: How AI systems “see” your business differently
AI systems now interpret your business through relationships, patterns, and structured meaning, not just text or keywords on a page. Here’s how they truly “see” your brand:
1. AI systems don’t just crawl — they synthesize
Instead of indexing pages independently, AI models fuse reviews, listings, social content, and website signals to generate a unified narrative about your brand.
Cloudflare’s 2024–25 radar report shows crawler traffic rising 18% year‑over‑year, with GPTBot requests up by roughly 300% and Googlebot nearly doubling. Publishers now have new controls (including pay-per-crawl features) to manage bot access, a reminder that crawlability and access policy are part of your AI indexing plan.
2. The shift from “keyword matching” to “entity understanding”
AI doesn’t rely on exact keyword matches. It focuses on entity relationships — who you are, what you offer, where you operate, and how customers perceive you, making contextual clarity more important than keyword density.
3. Traditional SEO is necessary but no longer enough
Meta tags and internal links still support crawlability, but they do not provide the depth AI needs. Large language models require explicit signals on identity, hierarchy, and context; without those, they improvise, which is how you end up with partially accurate or misplaced answers about your business.
4. Multi-location data is harder for AI to interpret
Without a clear hierarchy, AI struggles to link corporate → region → location, service variations, and geography, which can fragment visibility across AI-generated answers.
5. Everything you publish becomes training data
Every profile/bio, review site, social page, FAQs, and updates all feed AI models. When generating answers, AI pulls from all of it, accurate or not. This makes cross‑platform consistency less of a ‘nice‑to‑have’ SEO hygiene item and more of a hard requirement for being indexable and recommendable in AI answers.
6. Gaps in data create AI hallucinations
When your information is inconsistent across channels, AI fills the blanks itself. This leads to fabricated facts, wrong hours, incorrect services, or mismatched locations, which directly affect customer trust and conversion.
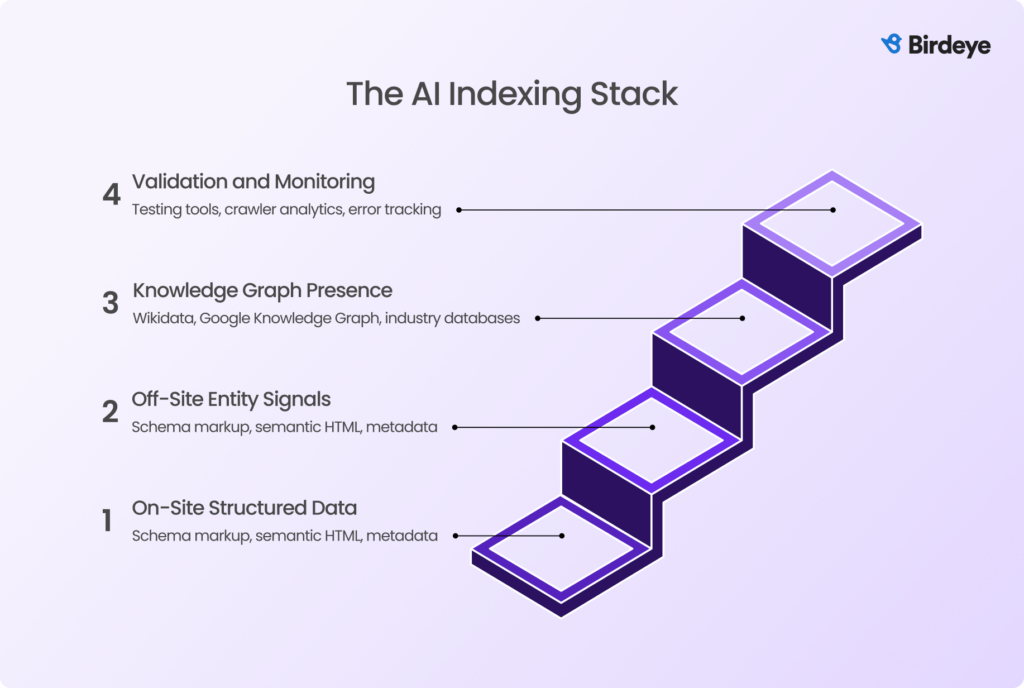
The AI indexing stack: The layers AI systems rely on
AI search engines evaluate your business through a layered ecosystem of structured data, entity signals, and validation workflows. This stack determines how accurately and how confidently AI systems can understand, classify, and recommend your brand across generative search experiences.
Schema Markup 2.0: Moving from SEO checkbox to AI communication protocol
Schema markup has shifted from “technical SEO enhancement” to the primary language AI systems use to understand, classify, and verify your business. In an AI‑first world, schema is less about rich snippets and more about telling models exactly who you are and how your entities relate.
Here’s how Schema Markup 2.0 works in an AI-first world:
The essential schema types for multi-location brands
Organization, LocalBusiness, Service, FAQPage, Review, and Person schema provide the core entity definitions AI relies on. Each type clarifies a different dimension of your business — corporate identity, location details, offerings, credibility signals, and expertise.
Nested schema architecture
AI needs to understand your hierarchy, not just your pages. Properly nesting the organization and Local Business Schema enables AI to follow corporate-to-location relationships and avoid blending information across branches.
Service schema depth
Basic service names are no longer enough. AI performs better when the service schema includes serviceType, areaServed, provider details, and descriptive properties that clarify what each location offers and how services differ.
Review and FAQ schema as AI training data
Structured review data gives AI verifiable evidence of customer experience, while FAQPage schema provides ready‑made question–answer pairs. Together, they help AI assess your reputation and present your information conversationally, rather than relying on unstructured text.
Birdeye State of Online Reviews 2025 report shows review volume rose 13% year‑over‑year, with Google’s share moving from roughly 79% to 81%, underscoring how central reviews and their markup have become for AI‑driven trust and recommendations.
Event and offer schema
Temporal data— sales, promotions, events, or seasonal hours helps AI provide up-to-date, context-specific answers. Schema ensures these time-bound details are recognized as current rather than static page content.
Breadcrumb and Site navigation element schema
These schema types help AI interpret your site structure and understand how content fits together. Clear navigation relationships reduce ambiguity and improve the model’s ability to classify and reference your pages correctly.
Common schema mistakes that confuse AI
Incomplete properties, conflicting information across pages, missing required fields, and improper nesting introduce uncertainty into AI’s reasoning. Even minor inconsistencies can warp the entity relationships AI depends on, leading to subtle but compounding errors in answers.
The schema priority matrix: What matters most for AI understanding
AI systems don’t treat all schema equally, some types form the foundation of your entity identity, while others amplify relevance, trust, and differentiation. This matrix helps multi-location brands prioritize the schema elements that most directly influence AI visibility and accuracy.

The multi-location data challenge: Building hierarchical entity architecture
For multi-location brands, AI search indexing depends on whether systems can accurately interpret the relationships between your corporate entity and each individual location. Without precise, structured signals, AI blends data, misattributes services, and confuses nearby branches more often than most teams realize.
Let’s have a look at how multi-location brands can structure this architecture effectively:
Corporate vs. location entity separation
AI must recognize your brand-level and location-level information as distinct. Separate but linked Organization and Local Business Schema prevent AI from merging attributes, ensuring corporate details don’t override location-specific facts and vice versa.
The parent–child relationship problem
Properties like branchOf and parentOrganization create a clear navigational path for AI. When implemented correctly, they allow AI to trace relationships across your hierarchy, helping it understand which information applies at which level.
Location-specific attribute management
Hours, services, staff, amenities, and specializations often vary by location. Structured, location-level data prevents AI from generalizing across branches and ensures each location is represented accurately in responses and recommendations.
Geographic disambiguation
Multiple stores within the same city or region can confuse AI without strong location identifiers. Clear NAP data, geo-coordinates, and unique attributes help models differentiate locations and avoid merging or misassigning details.
Franchise and multi-brand complexity
Franchises and parent companies operating multiple brands add another layer of complexity. The schema must reflect brand ownership, licensing relationships, co-located businesses, and shared services to avoid AI blending separate entities.
The centralized vs. distributed approach
Brands must decide whether the schema is controlled centrally through CMS templates or customized individually for each location. Centralized templates protect consistency; controlled local enhancements capture real‑world variation without breaking the underlying entity model.
Quality assurance for scale
With dozens or hundreds of locations, schema drift and errors are inevitable without governance. Automated validation, structured publishing workflows, and scheduled audits help maintain accuracy and prevent cascading AI misinterpretations.
Once the hierarchy is solid, the next step is expanding beyond the schema to the full set of data signals AI relies on.
Beyond Schema: The complete data layer for AI indexing
Schema is only one part of the AI search indexing equation. To fully understand your brand, AI systems draw from every structured and unstructured signal across your digital ecosystem— including feeds, metadata, accessibility layers, and machine-readable assets.
Here’s how to strengthen the full technical infrastructure AI relies on:
Knowledge graph integration
Getting your brand into major public knowledge sources like Google’s Knowledge Graph and Wikidata helps AI confirm your identity. These sources act as authoritative reference points that models use to validate facts and resolve ambiguity.
API accessibility
Creating structured data endpoints (JSON-LD APIs, XML sitemaps, RSS feeds) gives AI crawlers clean, consistent data to ingest. These machine‑readable feeds reduce reliance on brittle page parsing and give AI a clean, canonical view of your data.
Robots.txt and crawl optimization
Ensuring AI crawlers (ChatGPT-User, GPTBot, PerplexityBot, Claude-Web) can access your content is essential. Clear crawl rules prevent accidental blocking while helping you control which areas of your site AI models can index.
Canonical URL strategy
Canonicalization prevents AI from interpreting duplicate or near-duplicate pages as separate entities. Strong canonical rules ensure AI maps content to the correct source and doesn’t fragment your brand’s information.
Hreflang for multi-location/multi-language
Hreflang attributes clarify which content belongs to which geographic or language audience. For brands operating across regions, this prevents AI from blending content across countries or showing the wrong location in responses.
Image alt text and structured image data
AI vision models actively analyze visual content. Accurate alt text, captions, and structured image metadata help these systems understand what an image represents and reference it accurately in AI-generated answers.
Video metadata and transcripts
Structured metadata and accessible transcripts make videos discoverable, quotable, and indexable by AI models. Transcripts also provide a clean textual context that models can incorporate into recommendations and summaries.
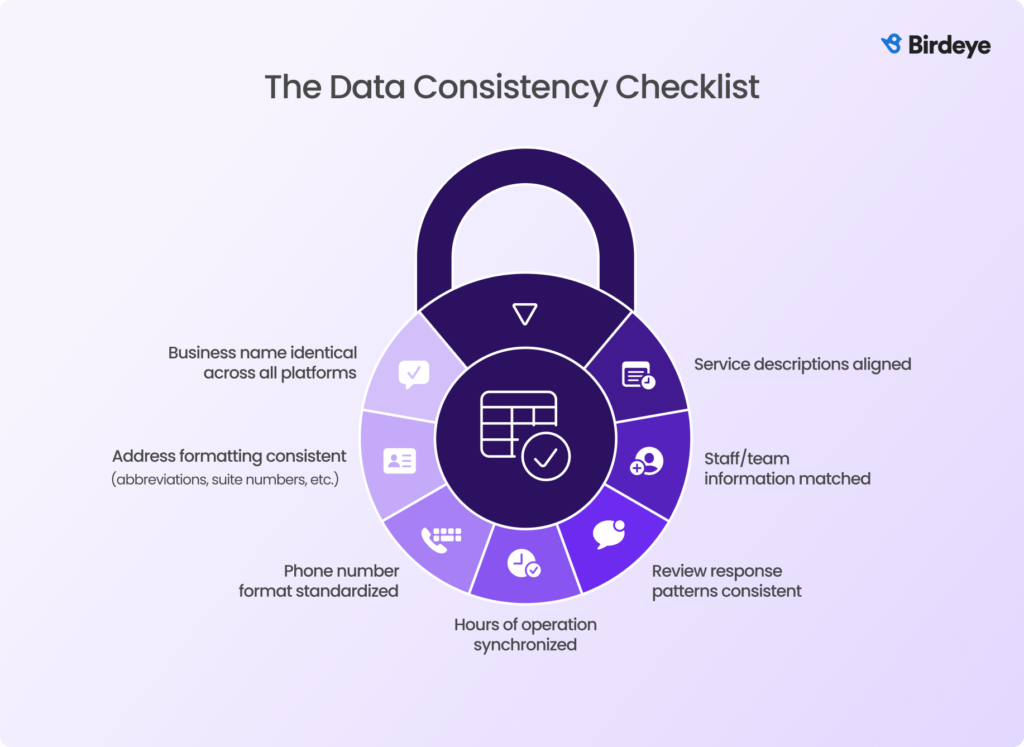
The data consistency checklist: Ensuring every external signal matches
AI models verify your identity through pattern recognition, and even small inconsistencies can weaken those signals. This checklist helps multi-location brands maintain uniform, trustworthy data across every platform AI relies on for entity validation.
The citation network: Building external data consistency
AI search indexing cross‑checks your website against the rest of the web, building an entity profile from every place your business appears. Every external platform that lists your business contributes to the “entity profile” AI systems build, shaping how confidently they can cite or recommend you.
Let’s look at the external data components that strengthen AI confidence in your brand:
NAP consistency across platforms
AI heavily depends on Name, Address, and Phone (NAP) uniformity to confirm a business entity. Mismatches across Google Business Profile, Apple Maps, Bing Places, directories, or social platforms teach AI that your identity is fuzzy, which makes it less willing to recommend you confidently.
Citation authority hierarchy
Not all listings carry equal weight. Platforms like Google, Apple, and major industry directories act as primary sources of truth for AI, helping models validate entity identity, geography, and core business attributes.
Review platform integration
AI scans review sites to understand customer sentiment, service quality, and credibility. Consistent business information across Yelp, TripAdvisor, industry verticals, and niche review sites prevents misattribution and strengthens entity coherence.
Social profile completeness
AI treats social channels as active identity signals. Fully completed LinkedIn, Facebook, Instagram, and X/Twitter profiles, especially with aligned bios, categories, and URLs reinforce your brand’s legitimacy and help AI confirm your public-facing details.
Industry directory presence
Trade associations, chambers of commerce, and vertical-specific directories serve as authoritative validators. Their structured listings help AI understand your category, specialization, and market relevance.
Press mentions and backlinks
Media coverage, partner listings, and high-quality backlinks signal authority and credibility. AI models look to these mentions to validate expertise and interpret your prominence within your category.
Data aggregator management
Aggregators like Localeze, Foursquare, and Factual distribute your business information across hundreds of secondary platforms. Clean, centralized aggregator data creates wide-reaching consistency AI relies on for accuracy.
Be the #1 answer on all AI engines
Want to see the impact of Birdeye on your business? Watch the Free Demo Now.
Practical implementation: The technical roadmap
Multi-location brands need a clear, phased approach that turns strategy into scalable execution across corporate and local properties. Here’s a step‑by‑step process to turn your AI indexing strategy into a working, AI‑friendly data architecture:
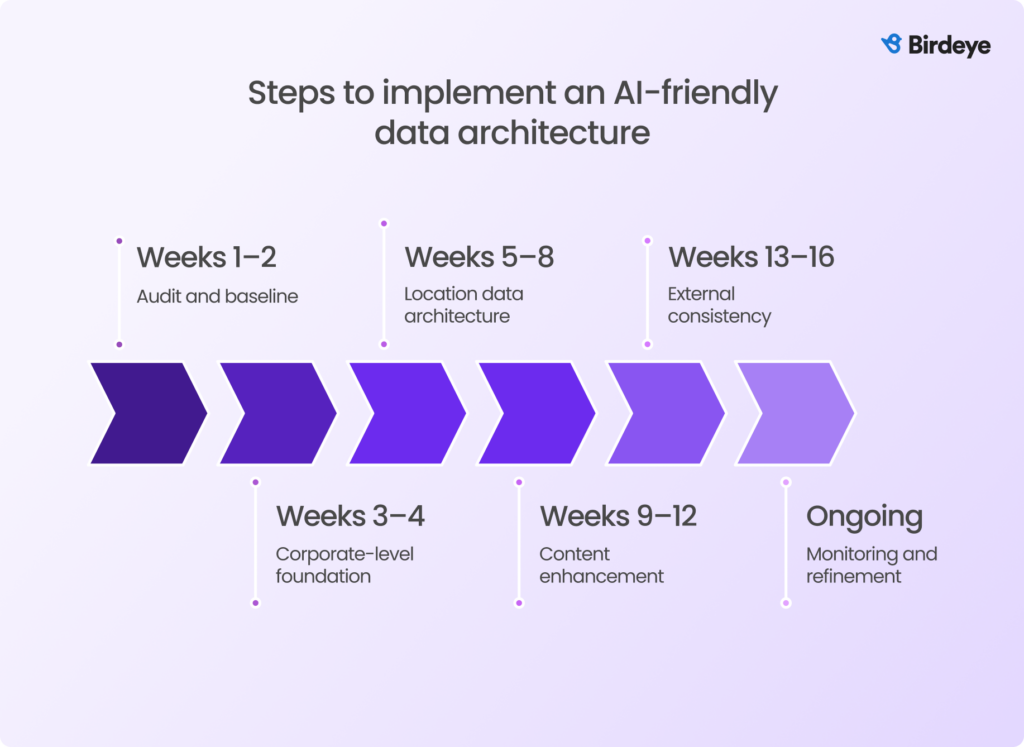
Phase 1: Audit and baseline (Weeks 1–2)
Start by assessing your existing schema, crawling infrastructure, and external citations. Use validation tools to identify missing fields, improper nesting, or conflicting entity signals that could confuse AI.
Tools and resources to manage multi-location schema at scale
Use Google's Rich Results Test, Schema.org validator, Screaming Frog for schema audits, Semrush/Ahrefs for technical SEO, BrightLocal/Yext for citation management. These tools streamline auditing, validation, and large-scale updates.
Phase 2: Corporate-level foundation (Weeks 3–4)
Implement a clean Organization schema to establish your top-level entity. This includes defining corporate identity, linking knowledge graph sources, and ensuring brand-level attributes are unambiguous and consistent.
Phase 3: Location data architecture (Weeks 5–8)
Roll out the LocalBusiness schema for each location, using proper parent-child hierarchy. Map service variations, hours, and staff information to the correct entity so AI can differentiate locations accurately.
Phase 4: Content enhancement (Weeks 9–12)
Enrich key pages with FAQ, Review, Article, and Service schema. This gives AI structured, contextual content to reference, especially for recommendation-style, conversational, and long-tail queries.
Phase 5: External consistency (Weeks 13–16)
Clean up citations across major platforms, directories, and review sites. Align NAP data, categories, and URLs, and ensure aggregator distributions match your internal source of truth.
Phase 6: Monitoring and refinement (Ongoing)
Continuously validate schema, monitor AI crawler logs, and track entity drift or inconsistencies. Ongoing refinement ensures your data stays accurate as business details evolve.
Before you implement the above-mentioned phases, quickly review the most common mistakes that can weaken your AI indexing signals.
Common implementation mistakes to avoid:
1. Mislabeling the corporate headquarters as a LocalBusiness instead of an Organization
2. Inconsistent business names across schema and citations (Inc. vs. LLC vs. abbreviated)
3. Missing required properties (telephone, address, opening hours, etc)
4. Duplicate schema markup causing conflicting signals
5. Outdated information in the schema that contradicts current operations
6. Over-optimization with keyword-stuffed descriptions in schema fields
Advanced techniques: Going beyond the basics
Now that the foundational elements are in place, let’s look at how multi-location brands can elevate their AI search performance with more sophisticated schema and content strategies.
These advanced techniques help AI systems deepen their understanding of your entities, strengthen semantic connections, and increase your odds of being chosen for richer AI‑generated answers and overviews.
Custom schema extensions
Create tailored, structured data layers that represent industry-specific attributes not covered by standard Schema.org types. This helps AI systems understand the nuances of your vertical, improving entity accuracy and relevance.
Dynamic schema generation
Automate schema creation using CMS logic, database records, or API feeds so structured data updates in real time. This ensures AI always reads the most current business information without manual intervention.
Multilingual schema implementation
Use language-specific properties such as inLanguage, alternateName, and localized descriptions to support global audiences. This improves entity recognition across regions and enhances visibility for non-English AI queries.
Event-driven schema updates
Set up triggers that instantly update the schema when key business events occur, like new services, revised operating hours, or staff changes. This reduces accuracy gaps and ensures AI never indexes outdated data.
Schema testing and experimentation
A/B test variations in schema depth, field completeness, and entity relationships to determine which configurations improve AI citation rates. Continuous experimentation helps refine what works for your industry and query set.
AI crawler analytics
Analyze server logs to understand how different AI crawlers like ChatGPT, Gemini, Perplexity, and others interact with your pages. Optimizing crawl paths and reducing render barriers increases structured data discovery and indexation.
Semantic HTML enhancement
Use semantic HTML5 elements, RDFa, and microformats alongside JSON-LD to reinforce meaning. This provides AI with additional context signals and helps validate relationships among content, structure, and schema.
Knowledge graph contribution
Actively contribute accurate information to Wikidata, DBpedia, and other open knowledge sources. These external references strengthen global entity recognition and help AI systems build consistent profiles of your brand.
Birdeye Search AI: Built to make AI search indexing real for multi-location brands
As AI‑driven discovery becomes central to how customers find businesses, Birdeye Search AI gives multi‑location brands a way to operationalize the indexing strategy described in this guide.
Instead of treating schema updates, citation audits, and knowledge‑graph work as disconnected projects, Search AI connects them to how AI engines actually crawl, interpret, and surface your brand.
Prompt and visibility analysis — understanding demand and AI behavior
Search AI tracks real prompts and questions people use when searching for services like yours on major AI platforms (ChatGPT, Gemini, Perplexity, etc.). This insight helps you align content, schema, and FAQ structure to the real prompts driving AI answers, which is the core of practical AI indexing.
Visibility, ranking, and share-of-voice tracking across locations and platforms
The platform allows you to monitor how often your brand and individual locations appear in AI-generated answers, and benchmark against competitors. You can track performance globally and locally by platform or region. This visibility layer complements on-site schema and data architecture by telling you whether AI engines are actually surfacing your information.
Citation and accuracy audits — ensuring consistent external data signals
Search AI identifies which citation sources AI engines rely on the most for your industry, and flags discrepancies in business information (hours, address, contact details, website links) across platforms.
Sentiment and brand representation monitoring
Beyond raw data, Search AI tracks how AI platforms interpret your brand: sentiment scores, key themes, strengths, and weaknesses.
Automated recommendations
Once it identifies gaps (in citations, content, data accuracy, and schema readiness), Search AI provides prioritized recommendations.
Continuous monitoring, benchmarking, and competitive intelligence
Search AI doesn’t offer a one-time audit — it provides ongoing visibility into how your brand performs across AI engines, how competitors stack up, and where opportunities or risks emerge.
Built from the ground up as a Generative Engine Optimization (GEO) platform, Birdeye Search AI is purpose-built for organizations with many locations. It handles prompt tracking, citation audits, content and schema optimization, and AI performance measurement across large footprints.
FAQs on AI search indexing
AI search indexing focuses on understanding entities, relationships, and context, not keywords or page snippets. Instead of matching queries to text, AI models reconstruct your business as an entity graph linking identities, attributes, and relationships across sources. This means structured data, consistent citations, and clear corporate-to-location hierarchy matter far more than keyword placement alone.
Multi-location brands have complex data: multiple addresses, varying services, different staff, and corporate–location relationships. AI systems need structured, unambiguous signals to understand which information belongs to which location. Without this clarity, AI blends data or invents details, leading to inaccurate answers.
Yes, modern AI systems treat your website, listings, reviews, and profiles as real-time training inputs. They don’t store your content permanently, but they learn patterns and facts to generate answers.
Reviews are one of the strongest entity confidence signals. AI systems use review sentiment, volume, recency, and response patterns to determine credibility and relevance.
Tools like Screaming Frog, server log analyzers, Semrush, Ahrefs, and custom bot-tracking setups help identify how AI crawlers visit your site. Specialized AI visibility tools like Birdeye Search AI help brands monitor their AI visibility across engines and recommendation surfaces.
Final thoughts
AI search indexing is an intentional, technical discipline. For multi-location brands, winning in AI-generated answers depends on how clearly and consistently your entity data is structured, connected, and reinforced across the web. Schema markup, citation networks, clean hierarchies, dynamic data updates, and knowledge graph influence all work together to help AI understand who you are, what you offer, and why you’re the best match for a query.
Brands that invest early in a unified AI indexing strategy will own more visibility, more recommendations, and more customer trust across the next generation of AI-driven search experiences. The businesses that build AI-ready infrastructure today will be the ones AI cites and recommends tomorrow.
Schedule a demo now to see Birdeye Search AI in action.

About the Author
Somya Yesodharan
Originally published